Linux高性能服务器编程基本看玩了, 现在需要进行实战练习, 然而从单纯的只会api到做出项目, 之间的距离
不是一般的小, 最终我选择了这本书…..
相关自己写的代码 大部分放在github 少部分会写在博客中
第一部分 C++多线程系统编程
第一章 线程安全的对象生命期管理
一个线程安全的class需要满足的条件
- 多个线程同时访问, 其表现出正确的行为
- 无论操作系统如何调度这些线程, 无论这些线程的执行顺序如何交织
- 调用端代码无需额外的同步或其他协调操作
对象构造的安全, 在构造期间不要泄露this指针, 如果不按照以下规定可能会早对象构造完成前就被访问
- 不要在构造函数中注册任何回调
- 不要在构造函数中把this传给跨线程的对象
- 即便在构造函数最后一行也不行, 因为对象可能是一个父类, 会先构造父类部分, 再构造子类部分
二段式构造有时候可以解决上面的问题
二段式构造-构造函数+initialize()
因为构造函数没有办法告知是否构造成功, 如果使用异常处理将会使代码复杂化.
比如在构造函数中使用new操作, 如果new操作失败就会出现不可预料的后果, 然后外部却无法知道
再比如将this传给其他跨线程对象, 如果构造结束前传入, 可能就会发生问题
shared_ptr的引出
如果在一个对象中通过指针访问资源(另一个对象), 知道这个资源是否活着是很难的.
如果简单的判断指针是否为空, 可能会在线程B已经判断了指针不为空还没有执行后续操作时, 线程A就把
这个资源释放掉了
当然可以通过资源管理对象 管理上面的资源, 但是也存在上面的问题.
所以要想安全的销毁对象最好在其他线程都看不到的情况下偷偷进行. (垃圾回收原理, 所有人用不到的东西一定是垃圾)
所以可以再资源管理对象中增加引用计数, 外部对象在释放资源管理对象中资源的时候, 只是将引用计数减一, 当引用计数为0的时候 在进行释放.
C++可能出现的内存问题
- 缓冲区溢出
使用std::vector<char>/std::string或者自己编写Buffer Class来管理缓冲区. 记住缓冲区长度, 通过成员函数而不是裸指针修改缓冲区 - 空悬指针/野指针
使用shared_ptr/weak_ptr - 重复释放
使用scoped_ptr, 只在对象析构的时候释放一次 - 内存泄漏
使用scoped_ptr, 对象析构时自动释放内存 - 不配对的new[]/delete
把new[] 统统替换成std::vector, scoped_array - 内存碎片
使用智能指针存在的一些问题
class Book
{
public:
Book(const std::string& name) :name_(name) {}
void DoSomething() {};
private:
std::string name_;
};
class BookShelf
{
public:
void Register(std::weak_ptr<Book> book)
{
books_.push_back(book);
}
void CheckBook()
{
// 锁争用
// 这里开头上锁 很可能影响其他的函数, 因为这里调用了用户提供的函数, 等待时间可能会非常长
// 比如Register函数就没有办法在这段时间中插入新的book
// mutex lock 开头上锁 保护vector
Iterator iter = books_.begin();
while (iter != books_.end())
{
std::shared_ptr<Book> obj(iter->lock());
if (obj)
{
obj->DoSomething();
iter++;
}
else
{
iter = books_.erase(iter);
}
}
}
private:
// 这样就强制要求了Book必须以shared_ptr管理
std::vector<std::weak_ptr<Book>> books_;
typedef std::vector<std::weak_ptr<Book>>::iterator Iterator;
};在对象的成员变量vector中保存shared_ptr 会导致管理的资源无法被释放, 因为引用计数最少为1.
如果保存weak_ptr可能会导致vector只增不减, 因为weak_ptr只管自己管理的资源, 不管自己.
通过定制shared_ptr的析构函数可以解决这个问题
如果将某个类的this指针 bind到一个function对象, 可能在函数调用时传进入一个已经被释放的对象地址
建议使用shared_ptr解决上面的问题, 如果想要获得this指针对应的shared_ptr, 可以另类继承enable_shared_from_this<T>, 通过在bind函数绑定shared_from_this()返回的shared_ptr.
class BookShelf:std::enable_shared_from_this<BookShelf>
{
public:
// Book对象固然可以销毁, 但是出现了轻微的内存泄漏
// book_只增不减!!!!. 虽然Book对象销毁了但是book_中依然保存着weak_ptr
// 所以需要定制析构功能
std::shared_ptr<Book> GetBook(const std::string &bookname)
{
std::shared_ptr<Book> pbook;
// 上锁
std::weak_ptr<Book>& wkbook = books_[bookname];
pbook = wkbook.lock();
if (!pbook)
{
// pbook.reset(new Book(bookname));
// 依然有问题 绑定this指针可能到时候this指向的对象已经不复存在了
// pbook.reset(new Book(bookname),
// std::bind(&BookShelf::DeleteBook, this, std::placeholders::_1));
// 注意shared_from_this不能在构造函数中调用, 因为构造Bookshelf的时候 他还没有
// 被交给shared_ptr管理
pbook.reset(new Book(bookname),
std::bind(&BookShelf::DeleteBook, shared_from_this(), std::placeholders::_1));
wkbook = pbook;
}
return pbook;
}
private:
std::map<std::string, std::weak_ptr<Book>> books_;
void DeleteBook(Book* book)
{
if (book)
{
// 上锁
books_.erase(book->GetName());
}
delete book;
}
};然而上面的代码依然有问题
依然有个问题. BookShelf的生命期似乎被意外延长了, 他不会短于function对象
所以改用weak_pr不就可以了吗
class BookShelf:std::enable_shared_from_this<BookShelf>
{
public:
std::shared_ptr<Book> GetBook(const std::string &bookname)
{
std::shared_ptr<Book> pbook;
std::weak_ptr<Book>& wkbook = books_[bookname];
pbook = wkbook.lock();
if (!pbook)
{
pbook.reset(new Book(bookname),
std::bind(&BookShelf::WkDeleteCallback,
std::weak_ptr<BookShelf>(shared_from_this()),
std::placeholders::_1));
wkbook = pbook;
}
return pbook;
}
private:
std::map<std::string, std::weak_ptr<Book>> books_;
void WkDeleteCallback(const std::weak_ptr<BookShelf> wk_shelf, Book* book)
{
std::shared_ptr<BookShelf> bookshelf(wk_shelf.lock());
if (bookshelf)
{
DeleteBook(book);
}
delete book;
}
void DeleteBook(Book* book)
{
if (book)
{
// 上锁
books_.erase(book->GetName());
}
}
};第一章已经读完了, 笔记只有上面那点. 我在学习Linux高性能服务器编程的大二上半年时间照着书边读边写笔记, 然后后来到了大二下我改成了读完一部分后脑中有什么记什么, 重要的地方如果记不清写不出来就去再看一下. 这样花费在记笔记的时间就少了很多, 写出来的笔记更加方便自己阅读.
第一章部分内容能看懂 真是谢了之前看的那个项目代码, 那个项目中大量使用了智能指针, 我在读哪个项目的代码的时候查了不少的东西, 现在才能看懂第一章的部分东西.
然而大部分?的东西感觉还是似懂非懂, 想写又写不出什么来. 我对于智能指针的使用还是过于晚了把.
第一章看来后续还要读一遍了
第二章 线程同步精要
线程同步的四项原则
按重要性排列
- 最低限度的共享对象, 减少需要同步的场合, 不用就不需要同步了nice!!!
- 使用高级的并发编程构建, 线程池, 队列, 倒计时
- 不得已使用底层同步原语时, 只使用非递归的互斥器和条件变量, 慎用读写锁, 不要用信号量
- 除了使用atomic整数外, 不要自己编写lock-free代码, 也不要用内核级的同步原语. 不凭空猜测
哪种做法性能更好 比如自旋锁和互斥锁
互斥器 mutex
使用mutex的原则
- 使用RAII手法封装mutex的创建销毁加锁解锁这四个操作, 不会因异常而忘记解锁
- 只使用非递归的mutex即不可重入的mutex
容易排查错误 使用递归mutex问题可能出现也可能不出现(可能由于逻辑问题对一个mutex加锁两次), 而使用非递归即可发现错误并改正 - 不手工调用lock()和unlock() 函数, 一切交给栈上的Guard对象的构造和析构函数负责
- Gruad对象的生命期正好等于临界区
次要原则
- 不使用跨进程的mutex, 进程间通信只用TCP sockets
- 加锁解锁在同一个线程 不会出现跨线程的操作 (RAII自动保证)
- 不忘记解锁(包括各种提前返回和异常抛出) 不重复解锁 均由RAII自动保证
- 必要时考虑用PTHREAD_MUTEX_ERRORCHECK来排错
封装MutexLock MutexLockGuard Condition
在Linux高性能服务器编程中 我也看过了封装mutex, 不过当时并没有使用RAII
从这里开始算是对RAII(Resource Acquisition Is Initialization)有了了解
https://zh.cppreference.com/w/cpp/language/raii
拥有open()/close()、lock()/unlock(),或 init()/copyFrom()/destroy()成员函数的类是非RAII类的典型例子
RAII将资源封装入一个类 如MutexLock类
- 构造函数请求资源, 建立所有类不变式, 或在无法完成时抛出异常
- 析构函数释放资源并绝不抛出异常
始终经由RALL类的实例使用满足要求的资源如MutexLockGuard类, 资源需满足 - 自身拥有自动存储期或临时生存期
- 或具有与自动或临时对象的生存期绑定的生存期
自己的理解就是经由RAII类生存期管理资源, RAII生存期开始即使用资源,
当RAII类生存期结束, RAII类中保存着的资源也自动销毁
RAII可以有效防止上面那些成对函数调用前一个后 由于异常抛出提前返回等 后一个函数没有被调用 造成资源状态异常
线程安全的Singleton实现
这个类在 flamingo 中也见到了, 这次是升级版
借由pthread_once保证线程安全
template <typename T>
class Singleton : noncopyable
{
public:
static T& GetInstance()
{
pthread_once(&ponce_, Init);
return *value_;
}
private:
Singleton();
~Singleton();
static void Init()
{
value_ = new T();
}
private:
static pthread_once_t ponce_;
static T *value_;
};
template <typename T>
pthread_once_t Singleton<T>::ponce_ = PTHREAD_ONCE_INIT;
template <typename T>
T* Singleton<T>::value_ = nullptr;copy-on-write?? copy-on-other-write!!
typedef std::pair<string, int> Entry;
typedef std::vector<Entry> EntryList;
typedef std::map<string, EntryList> Map;
typedef std::shared_ptr<Map> MapPtr;
MapPtr data_;好的现在数据存储在data_ 中 系统中存在多个读线程和一个写线程 针对data_
如果写线程不管不顾 有数据就往data_中写入 出现了读写进程同时访问data_就会出问题.
就书中描述来意思来说 不用大刀阔斧的使用读写锁, 能用mutex简单解决为什么要用读写锁.
那么如何保证读写安全呢?
当读进程读的时候 拷贝一次data_ data_的引用计数至少为2.
就在这时写进程判断 data_引用计数不为1, 于是拷贝原来指向的map, 然后将data_ reset指向新的map
这时data_引用计数变为1 可以正常写了. 而读进程中保存的map拷贝是稍久的 引用计数降为1, 执行完后就自动析构了旧数据
下面的代码 读部分只在GetData中加锁, 缩小了临界区
MapPtr GetData() const
{
// binding reference of type ‘MutexLock&’ to ‘const MutexLock’ discards qualifiers
MutexLockGuard lock(mutex_);
return data_;
}
int CustomerData::Query(const string &custmoner, const string &stock) const
{
MapPtr data = GetData();
Map::const_iterator entries = data->find(custmoner);
if (entries != data->end())
{
return FindEntry(entries->second, stock);
}
else
{
return -1;
}
}
void CustomerData::Update(const string &customer, const CustomerData::EntryList &entries)
{
MutexLockGuard lock(mutex_);
if (!data_.unique())
{
MapPtr new_data(new Map(*data_));
data_.swap(new_data);
// sawp后 先前某个线程通过GetData拿到MapPtr 他会读到稍旧的数据
}
assert(data_.unique());
(*data_)[customer] = entries;
}第三章 多线程服务器的适用场合与常用编程模型
单线程服务器常用的编程模型non-blocking IO + IO multiplexing 即为Reactor模式
程序的基本结构是一个事件循环, 以事件驱动和事件回调的方式实现业务逻辑
本质的缺点
要求事件回调函数必须是非阻塞的, 单线程还阻塞 这还怎么玩…
对于涉及网络IO的请求响应式协议, 容易割裂业务逻辑, 使其散布于多个回调函数中
多线程服务器常用编程模型
- 每个请求创建一个线程, 使用阻塞式IO操作
- 使用线程池, 同样是阻塞式IO操作
- 非阻塞IO + IO多路复用 即Java NIO方法
- 领导者追随者等高级模式
推荐的C++多线程服务器端编程模式为 one (event) loop per thread + thread pool
一个线程一个事件循环 + 线程池
事件循环用作IO多路复用, 配合非阻塞IO和定时器
线程池用作计算, 具体可以是任务队列或生产者消费者队列
必须使用单线程的场合
- 程序可能会fork
- 限制程序的CPU占用率 一个线程最多占满一个核心
适用多线程程序的场景
- 有多个CPU可用, 单核机器上多线程没有性能优势
- 线程间有共享数据, 否则建议使用 主进程+工作进程 每个进程都是单线程的模型
- 共享数据是可以修改的. 如果数据不能修改可以进程间使用共享内存
- 事件响应有优先级差异, 防止优先级反转
- 程序要有相当的计算量
- 利用异步操作
- 能享受到增加CPU数目带来的好处
- 多线程有有效地划分责任与功能
后面大部分我都是看看就过去了, 自己没有丝毫经验 也不打算现在细看
第四章 C++多线程系统编程精要
学习多线程编程面临的最大思维方式转变
- 当前进程随时可能被切出去
- 多线程程序中事件的发生顺序不再有全局统一的先后关系
常用的11个pthreads函数
- pthread_create() pthread_join()
- pthread_mutex_(create/destory/lock/unlock)
- pthread_cond_(create/destory/wait/signal/broadcast)
多线程系统编程的难点不在于学习线程原语, 而在于理解多线程与现有的C/C++库函数和系统调用的交互关系
以进一步学习如何设计并实现线程安全且高效的程序
pthread_t并不适合作为程序中对线程的标识符
- 他可能会同一进程的两个线程相同
- 或者是不利于打印
- 无法判断其是否非法
- 文件系统中没有对应项
- 脱离进程便没意义
推荐使用gettid()作为线程标识符
- 任何时刻都是全局唯一的
- 类型为pid_t通常为一个小整数利于在日志中打印.
- 0就是非法值1, 因为操作系统第一个进程init的pid是1
- 在现代Linux中, 他直接表示内核的任务调度id, 容易在/proc文件系统中找到对应项
- 在其他系统工具中也容易定位到某一个具体线程, 列如使用top按线程列出任务,
便可以找到线程id, 再根据程序日志判断是哪一个具体线程
// .h
extern __thread int t_cachedTid;
void cacheTid();
inline int tid()
{
if (__builtin_expect(t_cachedTid == 0, 0))
{
cacheTid();
}
return t_cachedTid;
}
// .cpp
__thread int t_cachedTid = 0;
void CurrentThread::cacheTid()
{
if (t_cachedTid == 0)
{
t_cachedTid = gettid();
}
}
// .cpp
pid_t gettid()
{
return static_cast<pid_t>(::syscall(SYS_gettid));
}thread
只能修饰POD类型, 不能修饰class类型, 因为无法自动调用构造析构函数. 可以用于修饰全局变量函数内的静态变量.是GCC内置的线程局部存储设施,存取效率可以和全局变量相比。thread变量每一个线程有一份独立实体,各个线程的值互不干扰.
builtin_expect
这个指令是gcc引入的,作用是允许程序员将最有可能执行的分支告诉编译器。这个指令的写法为:builtin_expect(EXP, N)。
意思是:EXP==N的概率很大. 就图中代码翻译过来就是 t_cachedTid == 0为0(假), 即为t_cachedTid最可能不是0.
- 使用同一个class创建线程, 全局统一. 一般不会为每个网络连接创建线程, 除非并发数与cpu数目相同
一个服务程序的线程数目应该与当前负载无关, 而应该有CPU数目有关. - 程序运行期间不要再创建和销毁线程, 最好在初始化的时候创建所有的线程
线程销毁的方式
- 正常死亡, 从线程主函数返回, 线程正常退出
- 非正常死亡, 从线程主函数抛出异常或线程触发segfault信号等非法操作
- 自杀 调用pthread_exit() 立刻终止线程
- 他杀 其他线程调用pthread_cancel() 来强制终止某个线程
线程只有一种正常死亡方式, 即第一种 其他方法都是错的Java中甚至把相关函数都废弃了
每个文件描述符只由一个线程操作, 从而解决消息收发的顺序问题, 把一个文件描述符读写分开未必会提高性能. 同时我们不知道epoll_wait阻塞的时候, 其他线程添加新的fd会发生什么. 为了稳妥起见应该把对同一个epollfd的操作放入同一个线程中执行.
包装文件描述符和连接
用Socket对象包装文件描述符
所有对此文件描述符的读写操作都通过此对象进行, 对象的析构函数里关闭文件描述符. 这样只要Socket对象还活着 就不会与其他Socket对象有相同的文件描述符, 也就不会发生串话. 包装文件描述符已经见过了, 同样是在flamingo中看到的.
用Tcpconnection包装连接
如果仅仅记住 fd = 8 这样的文件描述符, A线程accept后转身去处理业务B线程把 fd = 8 给关闭了!! 同时accept一个新的fd 同样是8!!. 这时A线程回复就会出现问题. 所以应该持有封装了Socket对象的Tcpconnection, 保证请求处理期间 文件描述符不会被关闭. 或者是持有Tcpconnection的弱引用. 这样就能知道 fd = 8 到底是原来的还是被关闭后新创建的. Tcpconnection对象不能提前销毁, 所以使用了shared_ptr来管理其生存期, 保证不会提前销毁造成串话.
第五章 高效的多线程日志
日志库大体分为前端和后端两部分, 两端之间的联系可能简单到只有一个函数
大多数感觉都是宏命令
日志的滚动也很重要 根据文件大小 和 时间 自动创建新的日志文件, 而不是全写入一个文件中
避免出现正则表达的元字符(列如我最喜欢的'['和']') 便于使用正则表达式查找
这一章的笔记是在我照着代码实现了简单的相似功能后才写的, 记录一下好的地方
大体分为了 LogStream类和Logger类 前者负责通过<<维护LogBuffer缓冲区, 后者做包装提供接口
LogBuffer使用了简单的数组作为缓冲区, 使用Append添加内容 维护写指针
LogStream重载了多种 参数情况, char和char* 很方便写入到缓冲区中
数字则需要转化成字符串
LogStream& operator<<(short num);
LogStream& operator<<(unsigned short num);
LogStream& operator<<(int num);
LogStream& operator<<(unsigned num);
LogStream& operator<<(long num);
LogStream& operator<<(unsigned long num);
LogStream& operator<<(long long num);
LogStream& operator<<(unsigned long long num);
LogStream& operator<<(char str);
LogStream& operator<<(const char* str);转化函数, 不得不说设计的真好. 通过模板解决了多种数字类型
const char digits_character[] = "0123456789";
// LEARN https://www.drdobbs.com/flexible-c-1-efficient-integer-to-string/184401596
template<typename T>
size_t Convert(char buff[], T value)
{
T i = value;
char* p = buff;
do
{
unsigned lsd = static_cast<unsigned>(i % 10);
i /= 10;
// *p++ = '0' + lsd; 不高效
*p++ = digits_character[lsd];
} while (i != 0);
if (value < 0)
{
*p++ = '-';
}
*p = '\0';
// LEARN 原文中是从buff最后一个字节开始写入 但是这里需要从开头写入 所以改为倒置一下
std::reverse(buff, p);
return p - buff;
}
template<typename T>
void LogStream::FormatInteger(T t)
{
if (buffer_.WriteableBytes() > MAX_NUMBER_SIZE)
{
size_t len = Convert(buffer_.WritePeek(), t);
buffer_.MoveWritePeek(len);
}
}将格式化也单独出了一个类
class Fmt
{
public:
template<typename T>
Fmt(const char* fmt, T val);
const char* GetData() const
{
return buff_;
}
int GetLength() const
{
return length_;
}
private:
char buff_[32];
size_t length_;
};
template<typename T>
Fmt::Fmt(const char* fmt, T val)
{
static_assert(std::is_arithmetic<T>::value == true, "Must be arithmetic type");
length_ = snprintf(buff_, sizeof buff_, fmt, val);
assert(length_ < sizeof buff_);
}Logger类的设计
方便了日志的打印, 实现了高效的转换
enum LogLevel
{
DEBUG,
INFO,
WARN,
ERROR,
FATAL,
NUM_LOG_LEVELS /* 仅用于表示LogLevel元素个数 不做实际使用 */
};
// LEARN 处处保持长度一致 使用NUM_LOG_LEVELS表示大小
const char* LogLevelName[Logger::NUM_LOG_LEVELS] =
{
"DEBUG ",
"INFO ",
"WARN ",
"ERROR ",
"FATAL ",
};字符串指针包装类, 减少strlen的调用 或者字符串没有终止
// LEARN 临时包装字符串指针和长度
class T
{
public:
T(const char* str, size_t len):
str_(str),
len_(len)
{
assert(strlen(str) == len);
}
const char* str_;
const size_t len_;
};使用内部类Impl包装了LogStream LogStream负责的是单纯的维护缓冲区 重载各种运算符.
Impl的构造函数输出了日志前边的固定部分
Logger的构造函数负责根据有无函数名等重载输出额外的固定内容
构造和析构之间完成 纯用户自定义部分输出
Logger的析构函数负责输出每条日志的结尾部分 文件名和行号
class Impl
{
public:
typedef Logger::LogLevel LogLevel;
Impl(LogLevel level, const SourceFile& file, int line);
void FormatTime();
void Finish();
Timestamp time_;
LogStream stream_;
LogLevel level_;
SourceFile filename_;
int line_;
};内部类SourceFile负责将__FILE__宏产生的字符数组转换成单纯的文件名. 使用了数组引用
class SourceFile
{
public:
/**
* 数组的引用 使数组在传参时不会降为 指针
*/
template<int N>
SourceFile(const char (&arr)[N]):
data_(arr),
size_(N - 1)
{
const char* name = strrchr(data_, '/'); /* /name */
if (name)
{
data_ = name + 1;
size_ -= static_cast<int>(data_ - arr);
}
}
const char* data_;
int size_;
};其他高效设计
// LEARN 缓存上一次输出的秒 同一秒输出时避免多次格式化
// 同一秒输出仅仅格式化 微秒部分
__thread char t_time[64];
__thread time_t t_last_second;第二部分 muduo网络库
第六章 muduo网络库简介
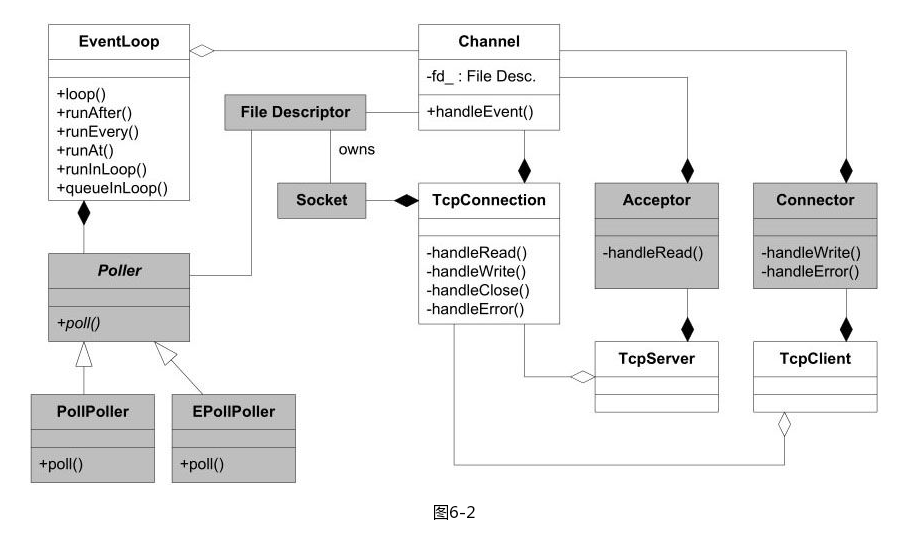
看完前面的一小部分, 我真心觉得这个库跟之前那个flamingo特别像, 估计这种管理方式就是某种主流方式?
估计我以后自己写的时候也是会按照这个模式来写了吧
TCP网络编程最本质的是处理三个半事件
- 连接的建立
- 连接断开 主动断开close 被动断开 read返回0
- 消息到达, 文件描述符可读. 最为重要的一个事件, 对它的处理方式决定了网络编程的风格.(阻塞还是非阻塞, 如何处理分包, 应用层缓冲如何设计)
- 消息发送完毕 这算半个
现在存在的问题
- 如果保证发送完应用层缓冲区数据才断开连接
自己思考的可以设立标志位, 如果设置了标志位发送完成后检测标志位 关闭连接 - 如果要主动发起连接, 但是对方主动拒绝, 如何定期重试
按照TCP重试机制 发送SYN 开启定时器 如果定时内没有收到确认ACK则重发SYN
这里了解到一个词 前向声明,
在程序设计中,前向声明(Forward Declaration)是指声明标识符(表示编程的实体,如数据类型、变量、函数)时还没有给出完整的定义。
通常为了简化头文件的关系 可以在A的头文件中 声明class B, 这样在你的代码中就可以使用B*而不需要引入B的头文件
第七章 muduo编程示例
本章大部分都是实战小例子, 自然要在代码中注释了.
博客这里就简单写一写
关于input buffer和output buffer已经有所了解过
output buffer在write调用一次没有发送完全的时候起到大用途. 一次没有发送完不应该等待在那里, 应该是接管这些未发送的数据, 阻塞代价是很大的. 应该是注册EPILOUT事件, 直到数据全部发送完毕. 否则就一直注册事件, 当然这是在连接正常的时候.
使用output buffer还有一个小问题, 一般情况下一次发送未完成才会使用到output buffer. 当缓冲区中存在数据的时候. 下一次的数据不能进行发送, 而应该是直接追加到尾部.
input buffer某种意义上作用更大, 这涉及到一个重要概念”粘包”的处理.
这里我了解到了capacity()机制, 可以用来减少内存分配次数. capacity()代表预分配的内存大小,
而size()是你写入的数据大小, 当size == capacity的时候再写入内容内存会分配更长的一个数组将旧数据拷贝过去size()依然是你写入的大小, capacity()则会变大
std::vector<char> buff(20); // 填充了20个元素 0
void Foo(size_t size)
{
buff.resize(size);
printf("%ld %ld\n", buff.size(), buff.capacity());
}
int main()
{
printf("%ld %ld\n", buff.size(), buff.capacity()); // 20 20
Foo(512); // 512 512
Foo(1024); // 1024 1024
Foo(1025); // 1025 2048
Foo(2048); // 2048 2048
Foo(2049); // 2049 4096
}花了小半天时间去了解配置了下 protobuf, 是一把很锋利的剑不错!
网络编程中使用protobuf的两个先决条件
- 长度问题, protobuf打包的数据没有自带长度信息或终结符, 这就需要程序自己在发送和接受的时候做正确的切分
- 类型问题, protobuf打包的数据没有自带类型信息, 需要由发送方把类型信息传给接收方, 接收方创建对应的具体protobuf message对象, 再做反序列化
我第一印象解决上面的方法, 就如书中所言是山寨的做法…. 增加header部分
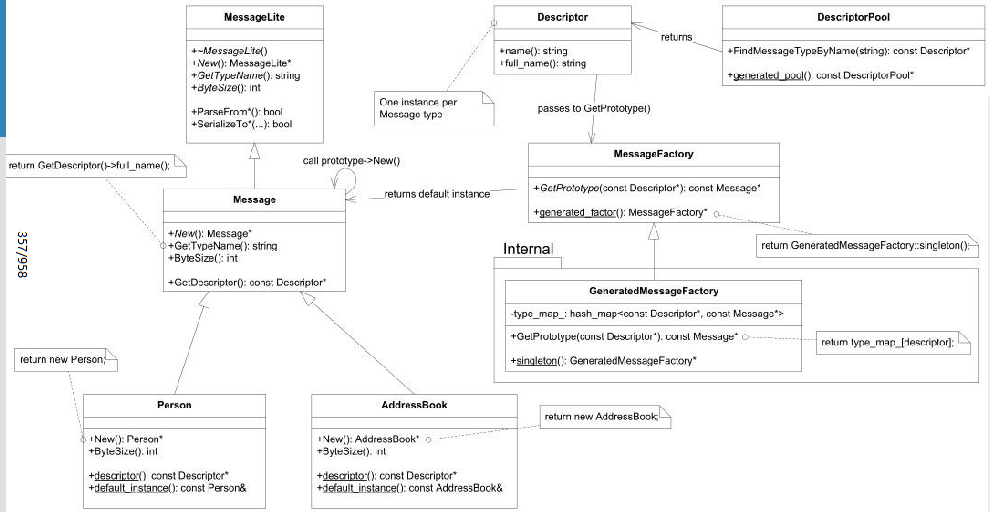 Protobuf类图
Protobuf类图
大概意思就是大部分人通过在头部增加代号标识消息类型(具体对应那个message), 而protobuf提供了
根据反射 根据typename 选择对应的Message对象的功能, 由于我没有用过protobuf 目前不是很了解 不过大概就这样了, 后续会专门学习 先用即可
// eg typename=muduo.Query
google::protobuf::Message* ProtobufCodec::createMessage(const std::string& typeName)
{
google::protobuf::Message* message = nullptr;
const google::protobuf::Descriptor* descriptor =
google::protobuf::DescriptorPool::generated_pool()->FindMessageTypeByName(typeName);
if (descriptor)
{
const google::protobuf::Message* prototype =
google::protobuf::MessageFactory::generated_factory()->GetPrototype(descriptor);
if (prototype)
{
message = prototype->New(); // 返回的是动态创建的指针
}
}
return message;
}
typedef std::shared_ptr<google::protobuf::Message> MessagePtr;
MessagePtr message;
message.reset(createMessage(typeName)); // 接管指针作者设计的格式如下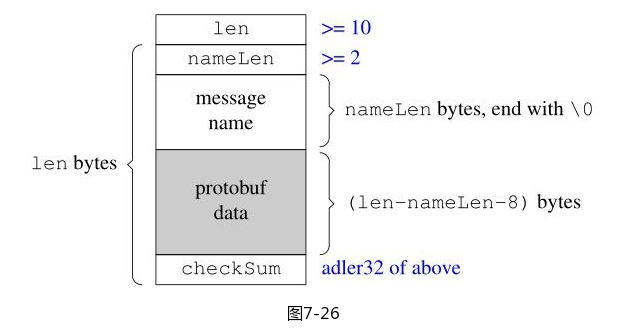
struct Foo
{
// int32_t version; 根本不需要版本号
int32_t len; // 没有使用uin32_t 是为了跨语言, Java没有unsigned
int32_t namelen;
char type_name[namelen]; // 以 /0 结尾 方便接收方处理 节省strlen() 空间换时间
char protobuf_data[len-namelen-8]
int32_t checksum; // adler32算法 进行校验
}终于知道编码器解码器合起来叫什么了… 编解码器(codec)
后面的一些例子就跳过了, 去准备阅读第八章然后动手写库了 这里才是重点 至于例子当时候自己再写.
自己的库不香吗?
第八章 muduo网路库设计与实现
第八章从第0节开始 一看就是程序员
这段时间我仿照muduo从中抽了部分功能做了自己的mongo库, 然后我将muduo Protobuf作为附属
改成了ProtobufServer(包装了TcpServer).
之后我便重新编写UE4部分的Protobuf收发部分的代码.
昨天晚上总算是将UE4打飞机的单机版 成功改造成了联机版. 使用的帧同步
服务器稳定性极佳, 而且内存占用很低, 想到了我之前写的Java服务器. 服务器CPU性能占用极少.
初期设计的时候 单机每秒发送12包, 每包平均0.16kb. 单机每秒就是2kb. 如果有6个客户端
服务器算上广播 出站流量 72kb/s
跑了下iftop看了下基本是这样.
12*6 = 72kb/s
阿里云送的服务器1Mbps, 理论可以支持8个客户端同屏游戏
阿里云学生机5Mbps, 理论支持17个客户端同屏游戏
当然了现在只同步了输入, 不过其他同步内容消耗的流量就很少了.
服务器程序运行良好, 倒是UE4 偶尔会崩….
后面慢慢完善打飞机和服务器
使用框架很简单的就实现了 登录和游玩数据分开 很舒服. 当然了登录目前只是个摆设没有在服务端保存
跳过登录依然可以玩, 后面完善db服务器再说