框架
后端组使用各种框架
- Java的Springboot
- Python的Django
框架的底层原理是什么? 当然涉及原理性的东西太多了, 我这里指的是为什么客户端的几次简单点击 最终会转化成了后端的函数调用?
Springboot针对某一个URL能Get Post等等设置对应的方法. 还能得到指定的参数?
客户端的几下简单的点击就能够将数据传送到后端 从后端拿回数据然后进行显示
后端也只要在相关的函数后处理接收到的数据
基础
要解释上面的问题需要用到计算机学院几门专业课的只是 <操作系统> <计算机组成原理 跳过> <计算机网络>
基础知识我要不要学? HTTP协议? DNS怎么发挥的作用?
GET POST 有什么区别? 为什么GET有参数长度限制(自己本以为是RFC规定 然而是浏览器规定的而且是URL长度限制而不是参数限制) 而POST没有参数长度限制
新了解到了
无法访问网页怎么办? 可以根据浏览器访问流程进行排查
校园网断网跳转怎么实现的? DNS污染又是什么? 返回错误的IP
favicon? 如何实现的自动加载 GET /favicon.ico HTTP/1.1
抓包的原理
浏览器访问流程
当你输入一个网址, 按下回车后 首先会向DNS服务器发送DNS请求将域名转换成IP. DNS污染
然后向 IP+端口号 建立连接 强调! 发送HTTP请求 (HTTP默认是80端口) 接收HTTP回应 进行解析HTML 然后请求相关的JS文件等
然而收发HTTP并不是 操作系统提供的基础API的功能 那是怎么来的?
HTTP协议
协议是什么?
文本协议
GET HTTP/1.1
Host: 10.2.5.251
Connection: keep-alive
DNT: 1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,ja;q=0.8
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
DNT: 1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,ja;q=0.8
Cookie: BIDUPSID=275AD930CBDC20F9C9E074230710B72E; PSTM=1602485007; BAIDUID=93E8E77E51A5F22CA01131559BA8666A:FG=1; BD_UPN=12314753; BDUSS=BjRVJYdFQ5TEJKWWNPck1ZcWdOVklMT0JHMHhQMUx3UGxDZjhNMVVhRmdqcXRmSVFBQUFBJCQAAAAAAAAAAAEAAADZQdlRcmpkNjc0NDEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGABhF9gAYRfM3; BDUSS_BFESS=BjRVJYdFQ5TEJKWWNPck1ZcWdOVklMT0JHMHhQMUx3UGxDZjhNMVVhRmdqcXRmSVFBQUFBJCQAAAAAAAAAAAEAAADZQdlRcmpkNjc0NDEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGABhF9gAYRfM3; BAIDUID_BFESS=F500721F63FBCA4EDC7DA170AE314FEE:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; COOKIE_SESSION=332523_0_8_0_3_6_1_0_7_4_42_0_332523_0_6_0_1604291277_0_1604291271%7C8%230_0_1604291271%7C1; sug=3; sugstore=0; ORIGIN=0; bdime=0; ZD_ENTRY=google
POST http://202.119.196.6:8080/Self/login/verify HTTP/1.1
Connection: keep-alive
Cache-Control: max-age=0
Origin: http://202.119.196.6:8080
Upgrade-Insecure-Requests: 1
DNT: 1
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://202.119.196.6:8080/Self/login/?302=LI
Accept-Language: zh-CN,zh;q=0.9,ja;q=0.8
Host: 202.119.196.6:8080
Accept-Encoding: gzip, deflate, br
Content-Length: 60
Cookie: JSESSIONID=E56420ED06E0ABE922C5A904DBB9C944
foo=&bar=&checkcode=1234&account=08180000&password=md5&code=
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2005 23:59:59 GMT
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 122
<html>
<head>
<title>Wrox Homepage</title>
</head>
<body>
<!-- body goes here -->
HTTP/1.1 200 OK Date: Sat
</body>
</html>根据这个格式描述一下格式 请求方法 请求路径 HTTP版本
HEADER部分 需要什么HEADER加入什么
BODY部分 放入数据
所根据的这个格式 这个规定就叫做协议 HTTP的规定就是HTTP协议
所以说你在手机上查询电费也好 电脑上浏览网页也罢 前端调用后端也是如此 只要是HTTP的API 都会将数据按照这个格式进行打包
- 建立连接后 Fiddler监听拦截的数据, 你知道了这个包的数据都有什么 然后自己建立连接发送同样的包 效果是一样的
- 发送打包的数据
- 接收服务器返回的结果
- 所以可以抓包后模拟请求这就这么来的
从TCP看HTTP
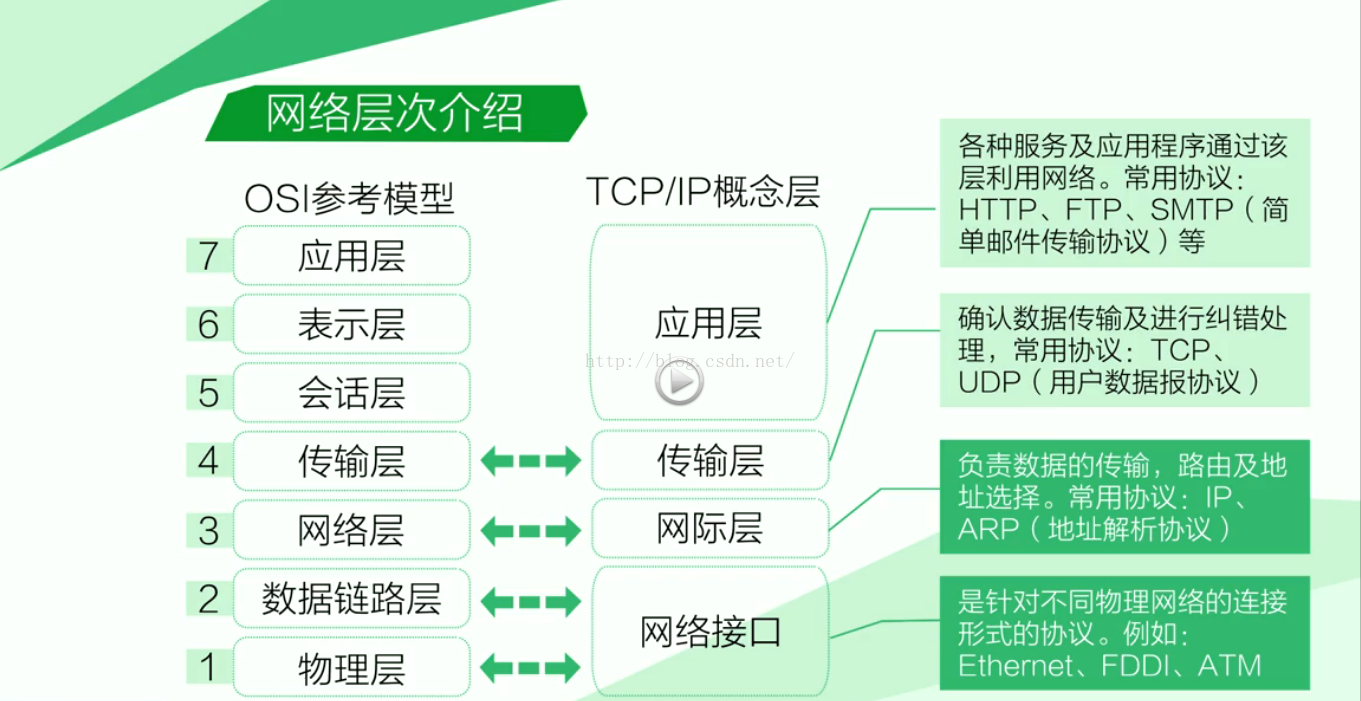
将根据这张图说一说, 经常让了解的 七层和四层协议. (网络访问(链接)层)
上边面说的建立连接建立的实际是TCP连接
TCP连接是通过 IP和端口号建立的 正好使用的上面的IP和端口号
TCP连接干什么? 连接就是传输数据 这就涉及到了读写操作 全双工
两个套接字之间的通信 客户端持有一个套接字 服务器持有一个套接字 然后客户端的数据发送和服务器端的数据接收就是转化为了针对套接字的读写
套接字你可以理解为 两个电话互相通话
套接字的建立和管理都比较复杂, 但是流程极为固定 干脆将这些代码包装起来 对外界提供一个简单的函数即可 内部帮你管理建立TCP连接
客户端指的就是你的浏览器也好, 你的应用也好 套接字这个核心的东西被包装了起来
所以输入网址也好, 使用form标签也罢. 最终都是根据HTTP协议包装你想要发送或者接受的数据. 建立TCP连接 然后将包装好的数据发送到套接字 对方从套接字接受 (流, 流水 按顺序流入)
nc 命令 演示演示?
所以你可以没有域名 照样可以使用HTTP协议 照样访问网页.
因为HTTP交互的核心就是 根据HTTP协议包装数据 经由TCP连接收发数据 TCP连接使用的是 IP和端口号 而非域名
域名就没有用了吗? 除了便于记忆? 域名 区分作用
HTTP框架
上面说了HTTP交互细节. 本质就是的收发
GET /api?a=1&b=2 HTTP/1.1
Host: 10.2.5.251
Connection: keep-alive
DNT: 1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,ja;q=0.8
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2005 23:59:59 GMT
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 122
<html>
<head>
<title>Wrox Homepage</title>
</head>
<body>
<!-- body goes here -->
</body>
</html>服务器端从套接字 接收到数据后 大家没有见过上面的东西吧
那就是框架接受之后 把它们作为字符串存了起来 然后按照HTTP的固定协议格式 将内容解析
必须解析的一般有 Get /api?a=1&b=2 然后得知了这是一个GET请求 请求的URL是 /api 有两个参数 叫什么 值是多少
然后根据你服务器代码设定的找到一个对应的函数, 框架调用这个函数 传入参数 你就可以处理相应的逻辑了.
库和框架?
库是帮你提供某些功能的包装, 单个库一般并不能开发完整的应用, 只是作为一部分功能函数. curl库 线程库
框架可以理解为库的升级版, 你使用一个框架提供的函数 就能开发完整的应用, 大多数框架还能方便的引入其他的库来供自己使用.
nginx?
nginx大家用过没有?
一般逻辑都是设置一个域名 然后指向一个端口 是不是?
域名这个东西就藏在了HTTPRequest的 header里 他同样从TCP连接接收数据 解析 便知道了域名 然后根据配置转发即可
要不要学基础知识?
端口 计算机网络 组装nas计网
网线到内核 操作系统和计算机组成原理
自学能力
我大一来的工作室 来的时候是远爷带我学的JavaWeb.
随便找了本Java书给划一下看哪里
给我指明了一个框架, 然后呢? 去学呗
百度->谷歌中文->谷歌英文 https://translate.google.cn/
知乎 百度 谷歌 Github StackOverflow 等等
遇到问题先百度
- 视频?
- 看书?
- 文档?
大二转LinuxC++ 全部都是从零开始 没有人带我
大学生
垃圾xxxA4 我就是不想学.
写博客?
人外有人天外有天
让自己一天比一天更加优秀 提升自己
平衡自己时间 爆肝程序
社交 我用大二上的社交换到了Linux入门 我退出了xxxx
大三上减肥(身高), 参加活动, 锻炼身体, 找对象? 规律作息
穿搭
多多质疑 乳酸菌饮料?
不要被轻易带节奏 12:55秒 https://www.bilibili.com/video/BV1jV411o7VV