N3.无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
int lengthOfLongestSubstring(string s)
{
bool char_flag[128]; // 记录字符是否出现过
int char_sub[128]; // 记录字符下标
memset(char_flag, false, sizeof char_flag);
int max_result = 0;
int begin_sub = 0;
int sub = 0;
while (sub < s.length())
{
char current_char = s[sub];
if (char_flag[current_char])
{
if (sub - begin_sub > max_result)
{
max_result = sub - begin_sub;
}
for (int i = begin_sub; i < char_sub[current_char]; ++i)
{
char_flag[s[i]] = false;
}
begin_sub = char_sub[current_char] + 1;
char_sub[current_char] = sub;
}
else
{
char_sub[current_char] = sub;
char_flag[current_char] = true;
}
sub++;
if (sub == s.length())
{
if (sub - begin_sub > max_result)
{
max_result = sub - begin_sub;
}
}
}
return max_result;
}
};思路是按顺序读取char, 如果没有出现过则标记出现记录下标.
如果出现了则用当前下标减去开始下标判断是否更长来记录, 同时更新开始下标为重复字符的下标后一个字符下标.
移动开始下标后 需要取消 新开始标记和旧开始标记之前的char标记
样例代码
class Solution {
public:
int lengthOfLongestSubstring(string s)
{
int heap[128] = {0};
int res = 0;
for(int i = 0, j = 0; j < s.size(); ++j)
{
heap[s[j]]++; // 标记字符出现
while(heap[s[j]] > 1) // 再次出现
{
/*
开始符号标记下标 向前滑动 1 将开始下标的字符滑动出去
如果滑出去的字符是本次遇到的重复字符 则继续 否则一直滑动到重复字符位置
*/
heap[s[i]]--;
i++;
}
res = max(res, j - i + 1);
}
return res;
}
};首先看上去 代码就非常的短 我的写了40行而这个仅有10行
改进
我的虽然不是一次滑动一个字符 而是滑动一步到位. 但是仍需要一个for循环来去掉滑出的字符. 所以同样例代码思想.
所以没有必要一次滑动到位, 反正for循环需要执行就在for之中慢慢滑动. 这样可以省去记录字符出现的下标
我字符出现记录使用的bool数组然而使用int数组却能包含更多的信息.
我原版代码需要额外判定一次是否到了尾部, 当最后一个字符没有重复的时候 循环就结束了.
N34.在排序数组中查找元素的第一个和最后一个位置
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
你的算法时间复杂度必须是 O(log n) 级别。
如果数组中不存在目标值,返回 [-1, -1]。
示例 1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: [3,4]示例 2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: [-1,-1]来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-first-and-last-position-of-element-in-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target)
{
int left = 0;
int right = nums.size();
while (left < right)
{
int sub = (right + left) >> 1;
if (target == nums[sub])
{
int l_sub, r_sub;
for (l_sub = sub - 1; l_sub >=0 && nums[l_sub] == target; --l_sub)
{
}
for (r_sub = sub + 1; r_sub <= nums.size() - 1 && nums[r_sub] == target; ++r_sub)
{
}
return {l_sub + 1, r_sub - 1};
}
else if (target < nums[sub])
{
right = sub;
}
else
{
left = sub + 1;
}
}
return {-1, -1};
}
};思路使用二分搜索找到目标元素 然后想左右扩散寻找边界
剑指 Offer 53 - I. 在排序数组中查找数字 I
统计一个数字在排序数组中出现的次数。
示例 1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: 2示例 2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: 0来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/zai-pai-xu-shu-zu-zhong-cha-zhao-shu-zi-lcof
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
int search(vector<int>& nums, int target)
{
int left = 0;
int right = nums.size();
while (left < right)
{
int sub = (right + left) >> 1;
if (target == nums[sub])
{
int result = 1;
for (int l_sub = sub - 1; l_sub >=0 && nums[l_sub] == target; --l_sub)
{
++result;
}
for (int r_sub = sub + 1; r_sub <= nums.size() - 1 && nums[r_sub] == target; ++r_sub)
{
++result;
}
return result;
}
else if (target < nums[sub])
{
right = sub;
}
else
{
left = sub + 1;
}
}
return 0;
}
};思路同上, 返回值不同
合并K个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6示例 2:
输入:lists = []
输出:[]示例 3:
输入:lists = [[]]
输出:[]来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/merge-k-sorted-lists
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* Merge(const vector<ListNode*>& lists, int left, int right)
{
if (right - left <= 1)
{
return lists[left];
}
else if (right - left == 2)
{
ListNode* node1 = lists[left];
ListNode* node2 = lists[left + 1];
if (!node1)
{
return node2;
}
else if (!node2)
{
return node1;
}
ListNode* head = new ListNode;
ListNode* node = head;
if (node1->val <= node2->val)
{
head->val = node1->val;
node1 = node1->next;
}
else
{
head->val = node2->val;
node2 = node2->next;
}
while (node1 != nullptr || node2 != nullptr)
{
if (!node1 || (node2 && node2->val <= node1->val))
{
node->next = new ListNode(node2->val);
node = node->next;
node2 = node2->next;
}
else if (node2 == nullptr || (node1 && node1->val < node2->val))
{
node->next = new ListNode(node1->val);
node = node->next;
node1 = node1->next;
}
}
return head;
}
else
{
int mid = (left + right) >> 1;
ListNode* node1 = Merge(lists, left, mid);
ListNode* node2 = Merge(lists, mid, right);
ListNode* result = Merge({ node1, node2 }, 0, 2);
return result;
}
}
ListNode* mergeKLists(vector<ListNode*>& lists)
{
if (lists.empty())
{
return nullptr;
}
return Merge(lists, 0, lists.size());
}
};思路的话比较简单 使用分治和递归. 将若干个ListNode*的合并的最终分解为 两两合并. 然后将合并结果再两两合并
第一版代码 我甚至没有delete临时用的指针… 有内存泄漏的问题 最终提交后 Time-33%…. 好吧
仔细想了下部分地方不需要这么多的拷贝 直接复用已有的ListNode*就行
代码2
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* Merge(const vector<ListNode*>& lists, int left, int right)
{
if (right - left <= 1)
{
return lists[left];
}
else if (right - left == 2) // 主要改动从这里开始
{
ListNode* node1 = lists[left];
ListNode* node2 = lists[left + 1];
if (!node1)
{
return node2;
}
else if (!node2)
{
return node1;
}
ListNode* head;
if (node1->val <= node2->val)
{
head = node1;
node1 = node1->next;
}
else
{
head = node2;
node2 = node2->next;
}
ListNode* node = head;
while (node1 != nullptr || node2 != nullptr)
{
if (!node1) // 同时在`node1`或`node2`为空的时候 直接append 避免额外的扫描
{
node->next = node2;
break;
}
else if (!node2)
{
node->next = node1;
break;
}
else
{
if (node2->val <= node1->val)
{
node->next = node2;
node = node->next;
node2 = node2->next;
}
else
{
node->next = node1;
node = node->next;
node1 = node1->next;
}
}
}
return head;
}
else
{
int mid = (left + right) >> 1;
ListNode* node1 = Merge(lists, left, mid);
ListNode* node2 = Merge(lists, mid, right);
ListNode* result = Merge({ node1, node2 }, 0, 2);
return result;
}
}
ListNode* mergeKLists(vector<ListNode*>& lists)
{
if (lists.empty())
{
return nullptr;
}
return Merge(lists, 0, lists.size());
}
};这次改动去掉了所有的new 因为直接复用已有的ListNode即可 同时在node1或node2为空的时候 直接append 避免额外的扫描
从Time-33%变化到了Time-67%
样例代码
class Solution {
public:
// 合并两个有序链表
ListNode* merge(ListNode* p1, ListNode* p2){ // 合并
if(!p1) return p2;
if(!p2) return p1;
if(p1->val <= p2->val){
p1->next = merge(p1->next, p2);
return p1;
}else{
p2->next = merge(p1, p2->next);
return p2;
}
}
ListNode* merge(vector<ListNode*>& lists, int start, int end){ // 负责拆分和合并
if(start == end) return lists[start];
int mid = (start + end) / 2;
ListNode* l1 = merge(lists, start, mid);
ListNode* l2 = merge(lists, mid+1, end);
return merge(l1, l2);
}
ListNode* mergeKLists(vector<ListNode*>& lists) {
if(lists.size() == 0) return nullptr;
return merge(lists, 0, lists.size()-1);
}
};这代码太精简了…
最长回文子串
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: "babad"
输出: "bab"
注意: "aba" 也是一个有效答案。示例 2:
输入: "cbbd"
输出: "bb"来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-palindromic-substring
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1 - 中心扩散法
class Solution {
public:
string longestPalindrome(string s)
{
/* 开头老套路 先处理了最简单的输入*/
if (s.length() <= 1)
{
return s;
}
/* 记录最大长度*/
int max_len = 0;
/* 记录最大长度子串的开始下标 用于return时的substr 解决拷贝问题*/
int result_begin_sub = 0;
int i = 0;
while (i < s.length())
{
int l_begin = i, r_begin = i;
/* 从当前下标开始 找到最长的相同字符子串*/
/* lbegin指向此子串的开始字符 rbegin指向结尾字符*/
while (r_begin < s.length() - 1 && s[r_begin + 1] == s[i])
{
r_begin++;
}
/* 更新下标 减少循环次数*/
i = r_begin + 1;
/* 向左右两侧遍历 相同字符则 向左移动lbegin 向右移动rbegin*/
do
{
l_begin--;
r_begin++;
}
while (l_begin >=0 && r_begin < s.length() && s[l_begin] == s[r_begin]);
/* 更新最大长度*/
int len = r_begin - l_begin - 1;
if (len > max_len)
{
max_len = len;
result_begin_sub = l_begin + 1;
}
}
return s.substr(result_begin_sub, max_len);
}
};遍历字符串 从当前循环开始下标找到最长的相同字符子串 如a 或 bb 或 ccc
然后向左右两侧遍历 如果左右字符相同 继续遍历 最终得到两个下标
左下标指向当前最大回文子串的左边一个字符 右下标指向右边一个字符
这样就得到了子串的开始下标和长度 更新最大长度 继续遍历
最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,”ace” 是 “abcde” 的子序列,但 “aec” 不是 “abcde” 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回 0。
示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace",它的长度为 3。示例 2:
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc",它的长度为 3。示例 3:
输入:text1 = "abc", text2 = "def"
输出:0
解释:两个字符串没有公共子序列,返回 0。提示:
1 <= text1.length <= 1000
1 <= text2.length <= 1000
输入的字符串只含有小写英文字符。来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-common-subsequence
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
int longest(const std::string& text1, const std::string& text2,
int text1_sub, int text2_sub)
{
if (text1_sub >= text1.length() || text2_sub >= text2.length())
{
return 0;
}
if (text1[text1_sub] == text2[text2_sub])
{
return 1 + longest(text1, text2, text1_sub + 1, text2_sub + 1);
}
else
{
return max(longest(text1, text2, text1_sub + 1, text2_sub),
longest(text1, text2, text1_sub, text2_sub + 1));
}
}
int longestCommonSubsequence(string text1, string text2)
{
return longest(text1, text2, 0, 0);
}最简单的思路 然而会超时
代码2 动态规划
int longestCommonSubsequence(string text1, string text2)
{
int result[1005][1005]{};
for (int i1 = 0; i1 < text1.length(); ++i1)
{
for (int i2 = 0; i2 < text2.length(); ++i2)
{
if (text1[i1] == text2[i2])
{
result[i1 + 1][i2 + 1] = result[i1][i2] + 1;
}
else
{
result[i1 + 1][i2 + 1] = max(result[i1][i2 + 1], result[i1 + 1][i2]);
}
}
}
return result[text1.length()][text2.length()];
}设text1和text2的解是T
- 如果text1和text2的最后两个字符相等, 则T的最后一个字符也是这个字符
这样 text1和text2分别去掉最后一个字符后, T去掉最后一个字符后的T1 是前面两个新字符串的最长公共子序列
- 如果最后两个字符不同, 则T可能是text1去掉最后一个字符后和text2的最长公共子序列 也可能是text2去掉最后一个字符后和text1的最长公共子序列
这个可以循环下去, 直到最后两个字符相等 转入上方过程
由于存在多种可能便需要设置result数组存储中间结果result[i][j]是text1前i个字符和text2前j个字符的最长公共子序列长度
数组填充方式 为上方描述的逆过程.
如果i1 i2所指字符相同
result[i][j]结果是result[i - 1][j - 1] + 1
表示的是text1前i-1字符和text2前j-1字符最长公共子序列 加上 这个相同的字符 得到前i和前j的最长公共子序列如果所指字符不同则
result[i][j]可能是result[i][j - 1]也可能是result[i][j - 1]取最大值
表示的是前ij的最长公共子序列是 text1前i字符和text2前j-1字符最长公共子序列 或者是 前i-1和前j的最长公共子序列
最终得到结果result[text1.length()][text2.length()] 表示前length1和前length2的最长公共子序列
E53.最大子序和
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4]
输出: 6解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/maximum-subarray
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
int maxSubArray(vector<int>& nums)
{
vector<int> b(nums.size());
b[0] = nums[0];
for (int i = 1; i < nums.size(); ++i)
{
if (b[i - 1] > 0)
{
b[i] = b[i - 1] + nums[i];
}
else
{
b[i] = nums[i];
}
}
int result = b[0];
for (int i = 1; i < b.size(); ++i)
{
if (b[i] > result)
{
result = b[i];
}
}
return result;
}
};代码2
class Solution {
public:
int maxSubArray(vector<int>& nums)
{
int numss = nums.size();
int temp = nums[0];
int result = nums[0];
for (int i = 1; i < numss; ++i)
{
temp = temp > 0 ? temp + nums[i] : nums[i];
result = result > temp ? result : temp;
}
return result;
}
};省去了一个vector 代码看起来也简洁不少
H51&H52N皇后
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
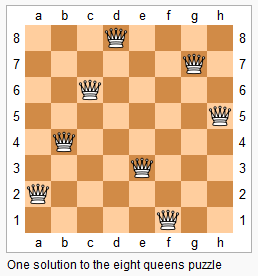
上图为 8 皇后问题的一种解法。
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
示例:
输入:4
输出:[
[".Q..", // 解法 1
"...Q",
"Q...",
"..Q."],
["..Q.", // 解法 2
"Q...",
"...Q",
".Q.."]
]解释: 4 皇后问题存在两个不同的解法。
提示:
- 皇后彼此不能相互攻击,也就是说:任何两个皇后都不能处于同一条横行、纵行或斜线上。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/n-queens
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
bool Check(int n, vector<string>& temp, int row, int column)
{
for (int c = 0; c < column; ++c)
{
if (temp[row][c] == 'Q')
{
return false;
}
}
for (int r = row - 1, c = column - 1 ; r >= 0 && c >= 0; --r, --c)
{
if (temp[r][c] == 'Q')
{
return false;
}
}
for (int r = row + 1, c = column - 1 ; r < n && c >= 0; ++r, --c)
{
if (temp[r][c] == 'Q')
{
return false;
}
}
return true;
}
void Solve(int n, int column, vector<string>& temp, vector<vector<string>>& result)
{
if (column >= n)
{
result.push_back(temp);
return;
}
for (int i = 0; i < n; ++i)
{
temp[i][column] = 'Q';
if (Check(n, temp, i, column))
{
Solve(n, column + 1, temp, result);
}
temp[i][column] = '.';
}
}
vector<vector<string>> solveNQueens(int n) // H51 N皇后
{
vector<vector<string>> result;
vector<string> temp(n, string(n, '.'));
Solve(n, 0, temp, result);
return result;
}
int totalNQueens(int n) // H52 N皇后
{
return solveNQueens(n).size();
}
};不知道第几次做了.. 思路很清晰
N55.跳跃游戏
给定一个非负整数数组,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个位置。
示例 1:
输入: [2,3,1,1,4]
输出: true
解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。示例 2:
输入: [3,2,1,0,4]
输出: false解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/jump-game
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
bool canJump(vector<int>& nums)
{
int level = 0;
int numss = nums.size();
while (level < numss)
{
if (nums[level] == 0)
{
int back_level = level - 1;
while (back_level >= 0 && back_level + nums[back_level] <= level)
{
back_level--;
}
if (back_level < 0)
{
break;
}
level = back_level + nums[back_level];
}
else
{
level += nums[level];
}
}
return level + 1 >= numss;
}
};能跳则跳最大长度, 不能跳则每一回退一个台阶 回退后的台阶必须能够跳到原台阶的后面位置
如果跳到numss上或者外说明能到, 如果因为回退回到了起点则不能跳过
代码2
class Solution {
public:
bool canJump(vector<int>& nums)
{
int numss = nums.size();
int max_level = 0;
for (int i = 0; i < numss; ++i)
{
if (i <= max_level)
{
max_level = max(max_level, i + nums[i]);
if (max_level >= numss - 1)
{
return true;
}
}
else
{
return false;
}
}
return false;
}
};然而真的需要回退吗? 可以遍历nums直接算能到的最大长度. 就算有0存在也不影响最远长度 能跳过0去在遍历到0前 max_level就已经跳过去了
516. 最长回文子序列
Difficulty: 中等
给定一个字符串 s ,找到其中最长的回文子序列,并返回该序列的长度。可以假设 s 的最大长度为 1000 。
示例 1:
输入:
"bbbab"输出:
4一个可能的最长回文子序列为 “bbbb”。
示例 2:
输入:
"cbbd"输出:
2一个可能的最长回文子序列为 “bb”。
提示:
1 <= s.length <= 1000s只包含小写英文字母
Solution
class Solution {
public:
int longestPalindromeSubseq(string s)
{
int ws = s.size();
int dp[ws][ws];
memset(dp, 0, sizeof dp);
for (int i = 0; i < ws; ++i)
{
dp[i][i] = 1;
}
for (int i = 1; i < ws; ++i)
{
for (int j = 0; j < ws - i; j += 1)
{
if (s[j] == s[j + i])
{
dp[j][j + i] = dp[j + 1][j + i - 1] + 2;
}
else
{
dp[j][j + i] = max(
dp[j + 1][j + i],
dp[j][j + i - 1]
);
}
}
}
return dp[0][ws - 1];
}
};整数反转
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
示例 1:
输入: 123
输出: 321示例 2:
输入: -123
输出: -321示例 3:
输入: 120
输出: 21注意:
假设我们的环境只能存储得下 32 位的有符号整数,则其数值范围为 [−231, 231 − 1]。请根据这个假设,如果反转后整数溢出那么就返回 0。来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/reverse-integer
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
int reverse(int x)
{
int result = 0;
while (x != 0)
{
int pop = x % 10;
x /= 10;
if (result > INT_MAX / 10 || (result == INT_MAX / 10 && pop > 7)) return 0; // 2^31 - 1 = 2147483647
if (result < INT_MIN / 10 || (result == INT_MIN / 10 && pop < -8)) return 0; // -2^31 = -2147483648
result = result * 10 + pop;
}
return result;
}
};汉诺塔
在经典汉诺塔问题中,有 3 根柱子及 N 个不同大小的穿孔圆盘,盘子可以滑入任意一根柱子。一开始,所有盘子自上而下按升序依次套在第一根柱子上(即每一个盘子只能放在更大的盘子上面)。移动圆盘时受到以下限制:
(1) 每次只能移动一个盘子;
(2) 盘子只能从柱子顶端滑出移到下一根柱子;
(3) 盘子只能叠在比它大的盘子上。
请编写程序,用栈将所有盘子从第一根柱子移到最后一根柱子。
你需要原地修改栈。
示例1:
输入:A = [2, 1, 0], B = [], C = []
输出:C = [2, 1, 0]示例2:
输入:A = [1, 0], B = [], C = []
输出:C = [1, 0]提示:
A中盘子的数目不大于14个。来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/hanota-lcci
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
void hanota(vector<int>& A, vector<int>& B, vector<int>& C)
{
int n = A.size();
move(n, A, B, C);
}
void move(int n, vector<int>& A, vector<int>& B, vector<int>& C){
if (n == 1)
{
C.push_back(A.back());
A.pop_back();
return;
}
move(n-1, A, C, B); // 将A上面n-1个通过C移到B
C.push_back(A.back()); // 将A最后一个移到C
A.pop_back(); // 这时,A空了
move(n-1, B, A, C); // 将B上面n-1个通过空的A移到C
}
};整数转罗马数字
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个整数,将其转为罗马数字。输入确保在 1 到 3999 的范围内。
示例 1:
输入: 3
输出: "III"示例 2:
输入: 4
输出: "IV"示例 3:
输入: 9
输出: "IX"示例 4:
输入: 58
输出: "LVIII"
解释: L = 50, V = 5, III = 3.示例 5:
输入: 1994
输出: "MCMXCIV"
解释: M = 1000, CM = 900, XC = 90, IV = 4.来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/integer-to-roman
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
代码1
class Solution {
public:
string intToRoman(int num)
{
std::string result;
auto p = [&](auto a, auto b)
{
result += a;
num -= b;
};
int time = num / 1000;
for (int i = 0; i < time; ++i)
{
p("M", 1000);
}
if (num >= 900)
{
p("CM", 900);
}
else if (num >= 500)
{
p("D", 500);
}
else if (num >= 400)
{
p("CD", 400);
}
time = num / 100;
for (int i = 0; i < time; ++i)
{
p("C", 100);
}
if (num >= 90)
{
p("XC", 90);
}
else if (num >= 50)
{
p("L", 50);
}
else if (num >= 40)
{
p("XL", 40);
}
time = num / 10;
for (int i = 0; i < time; ++i)
{
p("X", 10);
}
if (num >= 9)
{
p("IX", 9);
}
else if (num >= 5)
{
p("V", 5);
}
else if (num >= 4)
{
p("IV", 4);
}
time = num;
for (int i = 0; i < time; ++i)
{
p("I", 1);
}
return result;
}
};一堆if else 当时看到后第一时间想到的便是这个做法 然而代码太长了. 然而程序中都是重复的逻辑, 看一下样例答案
代码2
class Solution {
public:
string intToRoman(int num) {
int values[]={1000,900,500,400,100,90,50,40,10,9,5,4,1};
string reps[]={"M","CM","D","CD","C","XC","L","XL","X","IX","V","IV","I"};
string res;
for (int i=0; i<13; i++)
{
while (num>=values[i])
{
num -= values[i];
res += reps[i];
}
}
return res;
}
};同样的逻辑 样例代码却能够使用两个数组来打成….. 太妙了 而且修改起来也比较方便
226. Invert Binary Tree
Invert a binary tree.
Example:
Input:
4
/ \
2 7
/ \ / \
1 3 6 9
Output:
4
/ \
7 2
/ \ / \
9 6 3 1Trivia:
This problem was inspired by this original tweet by Max Howell:
Google: 90% of our engineers use the software you wrote (Homebrew), but you can’t invert a binary tree on a whiteboard so f*** off.
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* invertTree(TreeNode* root)
{
if (!root)
{
return nullptr;
}
TreeNode* temp = root->left;
root->left = root->right;
root->right = temp;
invertTree(root->left);
invertTree(root->right);
return root;
}
};116. 填充每个节点的下一个右侧节点指针
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
进阶:
你只能使用常量级额外空间。
使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。示例:
输入:root = [1,2,3,4,5,6,7]
输出:[1,#,2,3,#,4,5,6,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。提示:
树中节点的数量少于 4096
-1000 <= node.val <= 1000/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node* next;
Node() : val(0), left(NULL), right(NULL), next(NULL) {}
Node(int _val) : val(_val), left(NULL), right(NULL), next(NULL) {}
Node(int _val, Node* _left, Node* _right, Node* _next)
: val(_val), left(_left), right(_right), next(_next) {}
};
*/
class Solution {
public:
Node* connect(Node* root)
{
if (!root)
{
return root;
}
connectTwoNode(root->left, root->right);
return root;
}
void connectTwoNode(Node* node1, Node* node2)
{
if (!node1 || !node2)
{
return;
}
node1->next = node2;
connectTwoNode(node1->left, node1->right);
connectTwoNode(node2->left, node2->right);
connectTwoNode(node1->right, node2->left);
}
};114. 二叉树展开为链表
给定一个二叉树,原地将它展开为一个单链表。
例如,给定二叉树
1
/ \
2 5
/ \ \
3 4 6将其展开为:
1
\
2
\
3
\
4
\
5
\
6/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void flatten(TreeNode* root)
{
if (!root)
{
return;
}
flatten(root->left);
flatten(root->right);
TreeNode* right = root->right;
root->right = root->left;
root->left = nullptr;
TreeNode* temp = root;
while (temp->right)
{
temp = temp->right;
}
temp->right = right;
}
};450. 删除二叉搜索树中的节点
Difficulty: 中等
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 *key *对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
- 首先找到需要删除的节点;
- 如果找到了,删除它。
说明: 要求算法时间复杂度为 O(h),h 为树的高度。
示例:
root = [5,3,6,2,4,null,7]
key = 3
5
/ \
3 6
/ \ \
2 4 7
给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。
一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。
5
/ \
4 6
/ \
2 7
另一个正确答案是 [5,2,6,null,4,null,7]。
5
/ \
2 6
\ \
4 7代码1
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int GetMin(TreeNode* root)
{
while (root->left)
{
root = root->left;
}
return root->val;
}
TreeNode* deleteNode(TreeNode* root, int key)
{
if (!root)
{
return nullptr;
}
if (root->val == key)
{
if (!root->left)
{
return root->right;
}
else if (!root->right)
{
return root->left;
}
else
{
root->val = GetMin(root->right);
root->right = deleteNode(root->right, root->val);
}
}
else if (root->val < key)
{
root->right = deleteNode(root->right, key);
}
else if (root->val > key)
{
root->left = deleteNode(root->left, key);
}
return root;
}
};701. 二叉搜索树中的插入操作
Difficulty: 中等
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
示例 1:
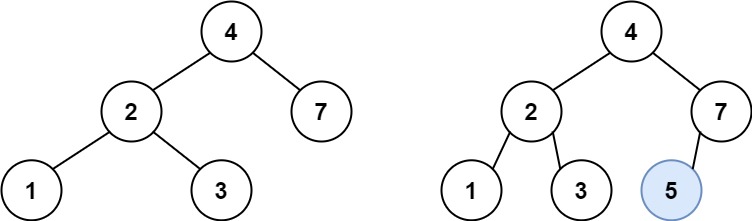
输入:root = [4,2,7,1,3], val = 5
输出:[4,2,7,1,3,5]
解释:另一个满足题目要求可以通过的树是:
示例 2:
输入:root = [40,20,60,10,30,50,70], val = 25
输出:[40,20,60,10,30,50,70,null,null,25]示例 3:
输入:root = [4,2,7,1,3,null,null,null,null,null,null], val = 5
输出:[4,2,7,1,3,5]提示:
- 给定的树上的节点数介于
0和10^4之间 - 每个节点都有一个唯一整数值,取值范围从
0到10^8 -10^8 <= val <= 10^8- 新值和原始二叉搜索树中的任意节点值都不同
代码1
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val)
{
if (!root)
{
return new TreeNode(val);
}
if (val < root->val)
{
root->left = insertIntoBST(root->left, val);
}
else if (val > root->val)
{
root->right = insertIntoBST(root->right, val);
}
return root;
}
};700. 二叉搜索树中的搜索
Difficulty: 简单
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
例如,
给定二叉搜索树:
4
/ \
2 7
/ \
1 3
和值: 2你应该返回如下子树:
2
/ \
1 3在上述示例中,如果要找的值是 5,但因为没有节点值为 5,我们应该返回 NULL。
代码1
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val)
{
if (!root)
{
return nullptr;
}
if (root->val == val)
{
return root;
}
else if (val < root->val)
{
return searchBST(root->left, val);
}
else if (val > root->val)
{
return searchBST(root->right, val);
}
return root;
}
};98. 验证二叉搜索树
Difficulty: 中等
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:
2
/ \
1 3
输出: true示例 2:
输入:
5
/ \
1 4
/ \
3 6
输出: false
解释: 输入为: [5,1,4,null,null,3,6]。
根节点的值为 5 ,但是其右子节点值为 4 。代码1
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
bool isValidBST(TreeNode* root, TreeNode* min, TreeNode* max)
{
if (!root)
{
return true;
}
if (min && root->val <= min->val)
{
return false;
}
if (max && root->val >= max->val)
{
return false;
}
return isValidBST(root->left, min, root) &&
isValidBST(root->right, root, max);
}
bool isValidBST(TreeNode* root)
{
return isValidBST(root, nullptr, nullptr);
}
};13. 罗马数字转整数
Difficulty: 简单
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
示例 1:
输入: "III"
输出: 3示例 2:
输入: "IV"
输出: 4示例 3:
输入: "IX"
输出: 9示例 4:
输入: "LVIII"
输出: 58
解释: L = 50, V= 5, III = 3.示例 5:
输入: "MCMXCIV"
输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.提示:
- 题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
- IC 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
- 关于罗马数字的详尽书写规则,可以参考 。
代码1
class Solution {
public:
int romanToInt(string s)
{
std::string k[] = {"M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"};
int v[] = {1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4 ,1};
int result = 0;
int s_sub = 0;
int k_sub = 0;
bool flag = true;
while (s_sub < s.length())
{
flag = true;
int i = 0;
for (;i < k[k_sub].length(); ++i)
{
if (s[s_sub + i] != k[k_sub][i])
{
k_sub++;
flag = false;
break;
}
}
if (flag)
{
s_sub += i;
result += v[k_sub];
}
}
return result;
}
};第一次写出的代码没有通过是因为使用了Map存储的kv然后使用iterator++遍历, 然而iterator遍历并不是按照初始化的顺序而是按照k的大小
代码2 - 样例
class Solution {
public:
int romanToInt(string s)
{
int m[256];
m['I'] = 1;
m['V'] = 5;
m['X'] = 10;
m['L'] = 50;
m['C'] = 100;
m['D'] = 500;
m['M'] = 1000;
int result=0;
for(int i = 0; i < s.size(); i++)
{
if(m[s[i]]>=m[s[i+1]])
{
result+=m[s[i]];
}
else
{
result-=m[s[i]];
}
}
return result;
}
};根据的原理是 把一个小值放在大值的左边,就是做减法,否则为加法。
此外样例中的m数组设计的也是很巧妙, 只初始化自己要使用的部分, 打破了我数组需要连续使用的思维定式
6. Z 字形变换
Difficulty: 中等
将一个给定字符串根据给定的行数,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 "LEETCODEISHIRING" 行数为 3 时,排列如下:
L C I R
E T O E S I I G
E D H N之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:"LCIRETOESIIGEDHN"。
请你实现这个将字符串进行指定行数变换的函数:
string convert(string s, int numRows);示例 1:
输入: s = "LEETCODEISHIRING", numRows = 3
输出: "LCIRETOESIIGEDHN"示例 2:
输入: s = "LEETCODEISHIRING", numRows = 4
输出: "LDREOEIIECIHNTSG"
解释:
L D R
E O E I I
E C I H N
T S G代码1
class Solution {
public:
string convert(string s, int numRows)
{
vector<vector<char>> vec(numRows, vector<char>(s.length(), ' '));
int column = 0;
int ss = 0;
while (ss < s.length())
{
for (int i = 0; ss < s.length() && i < numRows; ++i)
{
vec[i][column] = s[ss++];
}
column++;
for (int i = numRows - 2; ss < s.length() && i >= 1; --i)
{
vec[i][column] = s[ss++];
column++;
}
}
std::string result;
for (int i = 0; i < numRows; ++i)
{
for (int j = 0; j < s.length(); ++j)
{
if (vec[i][j] != ' ')
{
result += vec[i][j];
}
}
}
return result;
}
};654. 最大二叉树
Difficulty: 中等
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
- 二叉树的根是数组中的最大元素。
- 左子树是通过数组中最大值左边部分构造出的最大二叉树。
- 右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
示例 :
输入:[3,2,1,6,0,5]
输出:返回下面这棵树的根节点:
6
/ \
3 5
\ /
2 0
\
1提示:
- 给定的数组的大小在 [1, 1000] 之间。
代码1
class Solution {
public:
int GetMaxSub(vector<int>& nums, int left, int right)
{
int result = left;
for (int i = left + 1; i < right; ++i)
{
if (nums[i] > nums[result])
{
result = i;
}
}
return result;
}
TreeNode* constructMaximumBinaryTree(vector<int>& nums)
{
int max_sub = GetMaxSub(nums, 0, nums.size());
TreeNode* root = new TreeNode(nums[max_sub]);
ConstructMaximumBinaryTree(nums, 0, max_sub, nums.size(), root);
return root;
}
void ConstructMaximumBinaryTree(vector<int>& nums, int left, int mid, int right, TreeNode* root)
{
if (left < mid)
{
int l_max = GetMaxSub(nums, left, mid);
root->left = new TreeNode(nums[l_max]);
ConstructMaximumBinaryTree(nums, left, l_max, mid, root->left);
}
if (mid + 1 < right)
{
int r_max = GetMaxSub(nums, mid + 1, right);
root->right = new TreeNode(nums[r_max]);
ConstructMaximumBinaryTree(nums, mid + 1, r_max, right, root->right);
}
}
};自己的第一个思路就是通过ConstructMaximumBinaryTree给传入的root节点构造左子树和右子树
然后递归的给root的左子树和右子树构造子树
每次传入left mid right将数组切分为两段 左段构造root的左子树 右段构造root的右子树
代码2
class Solution {
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums)
{
return constructMaximumBinaryTree(nums, 0, nums.size());
}
TreeNode* constructMaximumBinaryTree(vector<int>& nums, int left, int right)
{
if (left + 1 > right)
{
return nullptr;
}
int max_sub = left;
for (int i = left + 1; i < right; ++i)
{
if (nums[i] > nums[max_sub])
{
max_sub = i;
}
}
TreeNode* node = new TreeNode(nums[max_sub]);
node->left = constructMaximumBinaryTree(nums, left, max_sub);
node->right = constructMaximumBinaryTree(nums, max_sub + 1, right);
return node;
}
};题解的答案更加的简洁每次的constructMaximumBinaryTree仅负责构造一个节点返回回去成为左节点或者右节点
同时给构造出的节点赋值左节点和右节点.
相对我的代码构造左节点和右节点 这里淡化了左右节点的区别. 通过传入的参数即可知道是左右节点然后赋值给left right
17. 电话号码的字母组合
Difficulty: 中等
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
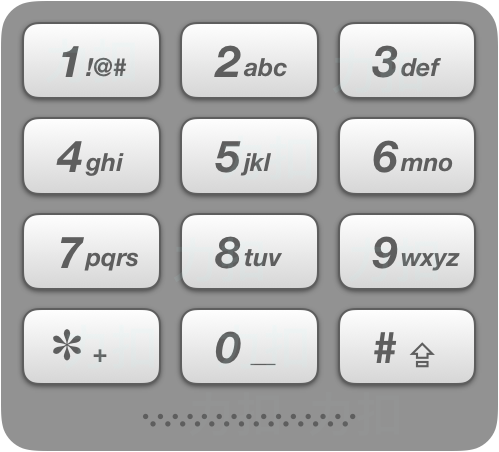
示例:
输入:"23"
输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"].说明:
尽管上面的答案是按字典序排列的,但是你可以任意选择答案输出的顺序。
Solution1
class Solution {
public:
vector<string> letterCombinations(string digits)
{
vector<string> result;
if (digits.empty())
{
}
else
{
solve(digits, 0, "", result);
}
return result;
}
void solve(const string& digits, int sub, string temp, vector<string>& result)
{
if (sub == digits.size())
{
result.push_back(temp);
}
else
{
char begin = (digits[sub] - '2') * 3 + 'a';
switch (digits[sub])
{
case '2':
case '3':
case '4':
case '5':
case '6':
{
for (int i = 0; i < 3; ++i)
{
char a = begin + i;
solve(digits, sub + 1, temp + a, result);
}
break;
}
case '7':
{
for (int i = 0; i < 4; ++i)
{
char a = begin + i;
solve(digits, sub + 1, temp + a, result);
}
break;
}
case '8':
{
begin += 1;
for (int i = 0; i < 3; ++i)
{
char a = begin + i;
solve(digits, sub + 1, temp + a, result);
}
break;
}
case '9':
{
begin += 1;
for (int i = 0; i < 4; ++i)
{
char a = begin + i;
solve(digits, sub + 1, temp + a, result);
}
break;
}
}
}
}
};19. 删除链表的倒数第N个节点
Difficulty: 中等
给定一个链表,删除链表的倒数第 _n _个节点,并且返回链表的头结点。
示例:
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.说明:
给定的 n 保证是有效的。
进阶:
你能尝试使用一趟扫描实现吗?
Solution1
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n)
{
if (!head)
{
return nullptr;
}
ListNode* node = head;
ListNode* temp = node;
ListNode* last_temp = nullptr;
int now_sub = 0;
while (node->next)
{
if (now_sub == n - 1)
{
last_temp = temp;
temp = temp->next;
node = node->next;
}
else
{
node = node->next;
now_sub++;
}
}
if (temp == head)
{
head = head->next;
}
else
{
last_temp->next = temp->next;
}
return head;
}
};21. 合并两个有序链表
Difficulty: 简单
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]示例 2:
输入:l1 = [], l2 = []
输出:[]示例 3:
输入:l1 = [], l2 = [0]
输出:[0]提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
Solution1
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2)
{
if (!l1)
{
return l2;
}
if (!l2)
{
return l1;
}
ListNode* head = nullptr;
if (l1->val < l2->val)
{
head = l1;
l1 = l1->next;
}
else
{
head = l2;
l2 = l2->next;
}
ListNode* temp = head;
while (l1 || l2)
{
if (!l1)
{
temp->next = l2;
break;
}
else if (!l2)
{
temp->next = l1;
break;
}
else
{
if (l1->val < l2->val)
{
temp->next = l1;
l1 = l1->next;
}
else
{
temp->next = l2;
l2 = l2->next;
}
temp = temp->next;
}
}
return head;
}
};24. 两两交换链表中的节点
Difficulty: 中等
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例 1:

输入:head = [1,2,3,4]
输出:[2,1,4,3]示例 2:
输入:head = []
输出:[]示例 3:
输入:head = [1]
输出:[1]提示:
- 链表中节点的数目在范围
[0, 100]内 0 <= Node.val <= 100
代码1
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* node)
{
if (!node)
{
return nullptr;
}
ListNode* temp = node->next;
if (!temp)
{
return node;
}
ListNode* back = temp->next;
temp->next = node;
node->next = swapPairs(back);
return temp;
}
};26. 删除排序数组中的重复项
Difficulty: 简单
给定一个排序数组,你需要在 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。
你不需要考虑数组中超出新长度后面的元素。示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}代码1
class Solution {
public:
int removeDuplicates(vector<int>& nums)
{
if (nums.empty())
{
return 0;
}
int t = 1;
int num = nums[0];
for (int i = 1; i < nums.size(); ++i)
{
if (nums[i] == num)
{
continue;
}
num = nums[i];
nums[t++] = nums[i];
}
return t;
}
};105. 从前序与中序遍历序列构造二叉树
Difficulty: 中等
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]返回如下的二叉树:
3
/ \
9 20
/ \
15 7代码1
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder)
{
return build(preorder, 0, preorder.size(),
inorder, 0, inorder.size());
}
TreeNode* build(vector<int>& preorder, int preb, int pree,
vector<int>& inorder, int inb, int ine)
{
if (preb == pree)
{
return nullptr;
}
TreeNode* root = new TreeNode(preorder[preb]);
int in_root;
for (in_root = inb; in_root < ine; ++in_root)
{
if (preorder[preb] == inorder[in_root])
{
break;
}
}
int num = in_root - inb;
root->left = build(preorder, preb + 1, preb + 1 + num, inorder, inb, in_root);
root->right = build(preorder, preb + 1 + num, pree, inorder, in_root + 1, ine);
return root;
}
};106. 从中序与后序遍历序列构造二叉树
Difficulty: 中等
根据一棵树的中序遍历与后序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
中序遍历 inorder = [9,3,15,20,7]
后序遍历 postorder = [9,15,7,20,3]返回如下的二叉树:
3
/ \
9 20
/ \
15 7代码1
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder)
{
return build(inorder, 0, inorder.size(), postorder, 0, postorder.size());
}
TreeNode* build(vector<int>& inorder, int inb, int ine, vector<int>& postorder,
int pob, int poe)
{
if (inb == ine)
{
return nullptr;
}
TreeNode* root = new TreeNode(postorder[poe - 1]);
int in_root;
for (in_root = inb; in_root < ine; ++in_root)
{
if (inorder[in_root] == postorder[poe - 1])
{
break;
}
}
int num = in_root - inb;
root->left = build(inorder, inb, in_root, postorder, pob, pob + num);
root->right = build(inorder, in_root + 1, ine, postorder, pob + num, poe - 1);
return root;
}
};652. 寻找重复的子树
Difficulty: 中等
给定一棵二叉树,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。
两棵树重复是指它们具有相同的结构以及相同的结点值。
示例 1:
1
/ \
2 3
/ / \
4 2 4
/
4下面是两个重复的子树:
2
/
4和
4因此,你需要以列表的形式返回上述重复子树的根结点。
Solution1
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<TreeNode*> result_;
map<string, int> node_map_;
vector<TreeNode*> findDuplicateSubtrees(TreeNode* root)
{
solve(root);
return result_;
}
string solve(TreeNode* root)
{
if (!root)
{
return "#";
}
string left = solve(root->left);
string right = solve(root->right);
string sum = left + "," + right + "," + to_string(root->val);
if (node_map_.find(sum) == node_map_.end())
{
node_map_.insert({sum, 1});
}
else
{
if (node_map_[sum] == 1)
{
result_.push_back(root);
}
node_map_[sum]++;
}
return sum;
}
};322. 零钱兑换
Difficulty: 中等
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1示例 2:
输入:coins = [2], amount = 3
输出:-1示例 3:
输入:coins = [1], amount = 0
输出:0示例 4:
输入:coins = [1], amount = 1
输出:1示例 5:
输入:coins = [1], amount = 2
输出:2提示:
1 <= coins.length <= 121 <= coins[i] <= 2<sup>31</sup> - 10 <= amount <= 10<sup>4</sup>
Solution - dp自顶向下
class Solution {
public:
vector<int> table;
// map<int, int> table;
int dp(vector<int>& coins, int amount)
{
if (amount == 0)
{
return 0;
}
else if (amount < 0)
{
return -1;
}
else if (table[amount] != 0)
{
return table[amount];
}
int result = INT_MAX;
for (int i = 0; i < coins.size(); ++i)
{
int temp = dp(coins, amount - coins[i]);
if (temp < 0)
{
continue;
}
result = min(temp + 1, result);
}
result = (result == INT_MAX ? -1 : result);
table[amount] = result;
return result;
}
int coinChange(vector<int>& coins, int amount)
{
if (amount < 1)
{
return 0;
}
table.resize(amount + 1);
return dp(coins, amount);
}
};72. 编辑距离
Difficulty: 困难
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入:word1 = "horse", word2 = "ros"
输出:3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')示例 2:
输入:word1 = "intention", word2 = "execution"
输出:5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')提示:
0 <= word1.length, word2.length <= 500word1和word2由小写英文字母组成
Solution 回溯
class Solution {
public:
int min_time = INT_MAX;
int minDistance(string word1, string word2)
{
minDistance(word1, word2, 0, 0, 0);
return min_time;
}
void minDistance(string word1, string word2, int ws1, int ws2, int time)
{
if (time >= min_time)
{
return;
}
if (ws2 == word2.length() || ws1 == word1.length())
{
for (int i = 0; i < min(ws1, ws2); ++i)
{
if (word1[i] != word2[i])
{
return;
}
}
time += word1.length() > word2.length() ? word1.length() - word2.length() : word2.length() - word1.length();
if (time < min_time)
{
min_time = time;
}
}
else
{
if (word1[ws1] == word2[ws2])
{
minDistance(word1, word2, ws1 + 1, ws2 + 1, time);
}
else
{
char back = word1[ws1];
word1[ws1] = word2[ws2];
minDistance(word1, word2, ws1 + 1, ws2 + 1, time + 1);
word1[ws1] = back;
string back_str = word1;
word1.erase(ws1, 1);
minDistance(word1, word2, ws1, ws2, time + 1);
word1 = back_str;
word1.insert(ws1, 1, word2[ws2]);
minDistance(word1, word2, ws1 + 1, ws2 + 1, time + 1);
}
}
}
};Solution DP备忘录
class Solution {
public:
map<string, int> bwl;
int minDistance(string word1, string word2)
{
return minDistance(word1, word2, word1.length() - 1, word2.length() - 1);
}
int minDistance(const string& word1, const string& word2, int ws1, int ws2)
{
if (ws1 == -1) return ws2 + 1;
if (ws2 == -1) return ws1 + 1;
string key = to_string(ws1) + "#" + to_string(ws2);
if (bwl.find(key) != bwl.end())
{
return bwl[key];
}
if (word1[ws1] == word2[ws2])
{
bwl[key] = minDistance(word1, word2, ws1 - 1, ws2 - 1);
}
else
{
bwl[key] = min({
minDistance(word1, word2, ws1, ws2 - 1), // 插入
minDistance(word1, word2, ws1 - 1, ws2 - 1), // 替换
minDistance(word1, word2, ws1 - 1, ws2) // 删除
}) + 1;
}
return bwl[key];
}
};Solution DP Table
class Solution {
public:
int minDistance(string word1, string word2)
{
int dp[word1.length() + 1][word2.length() + 1];
dp[0][0] = 0;
for (int i = 1; i <= word2.length(); ++i)
{
dp[0][i] = i;
}
for (int i = 1; i <= word1.length(); ++i)
{
dp[i][0] = i;
}
for (int ws1 = 1; ws1 <= word1.length(); ++ws1)
{
for (int ws2 = 1; ws2 <= word2.length(); ++ws2)
{
if (word1[ws1 - 1] == word2[ws2 - 1])
{
dp[ws1][ws2] = dp[ws1 - 1][ws2 - 1];
}
else
{
dp[ws1][ws2] = min({
dp[ws1 - 1][ws2 - 1],
dp[ws1][ws2 - 1],
dp[ws1 - 1][ws2]
}) + 1;
}
}
}
return dp[word1.length()][word2.length()];
}
};总结
使用回溯法的代码超时了, 而且回溯解法里面对字符串进行了实打实的修改
从回溯法转向DP备忘录优化了一个参数 使用返回值返回答案而不是单独的time参数. DP备忘录由于使用了递归所以使用的空间大, 效率也低
观察DP备忘录dp[ws1][ws2]只跟dp[ws1-1][ws2-1], dp[ws1][ws2-1]和dp[ws1-1][ws2]有关进而自然的转向DP Table
Dp Table这里数组一般都需要多开一行+一列 对应代码里面的length()+1, 否则下标0含有两层意思 一是空串时长度为0 二是非空串是含有0这个有效下标
所以将非空串的下标改为从1开始
354. 俄罗斯套娃信封问题
Difficulty: 困难
给定一些标记了宽度和高度的信封,宽度和高度以整数对形式 (w, h) 出现。当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算最多能有多少个信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
说明:
不允许旋转信封。
示例:
输入: envelopes = [[5,4],[6,4],[6,7],[2,3]]
输出: 3
解释: 最多信封的个数为 3, 组合为: [2,3] => [5,4] => [6,7]。Solution
class Solution {
public:
int maxEnvelopes(vector<vector<int>>& envelopes)
{
if (envelopes.empty())
{
return 0;
}
sort(envelopes.begin(), envelopes.end(), [](const auto& lhs, const auto& rhs){
if (lhs[0] != rhs[0])
{
return lhs[0] < rhs[0];
}
else
{
return lhs[1] > rhs[1];
}
});
int nums[envelopes.size()];
for (int i = 0; i < envelopes.size(); ++i)
{
nums[i] = envelopes[i][1];
}
int dp[envelopes.size()];
int result = 1;
for (int i = 0; i < envelopes.size(); ++i)
{
dp[i] = 1;
for (int j = 0; j < i; ++j)
{
if (nums[j] < nums[i] && dp[j] >= dp[i])
{
dp[i] = dp[j] + 1;
if (dp[i] > result)
{
result = dp[i];
}
}
}
}
return result;
}
};300. 最长递增子序列
Difficulty: 中等
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。示例 2:
输入:nums = [0,1,0,3,2,3]
输出:4示例 3:
输入:nums = [7,7,7,7,7,7,7]
输出:1提示:
1 <= nums.length <= 2500-10<sup>4</sup> <= nums[i] <= 10<sup>4</sup>
进阶:
- 你可以设计时间复杂度为
O(n<sup>2</sup>)的解决方案吗? - 你能将算法的时间复杂度降低到
O(n log(n))吗?
Solution
class Solution {
public:
int lengthOfLIS(vector<int>& nums)
{
int dp[nums.size()];
dp[0] = 1;
for (int i = 1; i < nums.size(); ++i)
{
dp[i] = 1;
for (int j = 0; j < i; ++j)
{
if (nums[j] < nums[i] && dp[j] >= dp[i])
{
dp[i] = dp[j] + 1;
}
}
}
int result = 0;
for (int i = 0; i < nums.size(); ++i)
{
if (dp[i] > result)
{
result = dp[i];
}
}
return result;
}
};583. 两个字符串的删除操作
Difficulty: 中等
给定两个单词 _word1 _和 _word2_,找到使得 _word1 _和 _word2 _相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
示例:
输入: "sea", "eat"
输出: 2
解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"提示:
- 给定单词的长度不超过500。
- 给定单词中的字符只含有小写字母。
Solution
class Solution {
public:
int minDistance(string word1, string word2)
{
int ws1 = word1.size();
int ws2 = word2.size();
int dp[ws1 + 1][ws2 + 1];
for (int i = 0; i <= ws1; ++i)
{
dp[i][0] = i;
}
for (int i = 0; i <= ws2; ++i)
{
dp[0][i] = i;
}
for (int i = 1; i <= ws1; ++i)
{
for (int j = 1; j <= ws2; ++j)
{
if (word1[i - 1] == word2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1];
}
else
{
dp[i][j] = min(
dp[i - 1][j],
dp[i][j - 1]
) + 1;
}
}
}
return dp[ws1][ws2];
}
};712. 两个字符串的最小ASCII删除和
Difficulty: 中等
给定两个字符串s1, s2,找到使两个字符串相等所需删除字符的ASCII值的最小和。
示例 1:
输入: s1 = "sea", s2 = "eat"
输出: 231
解释: 在 "sea" 中删除 "s" 并将 "s" 的值(115)加入总和。
在 "eat" 中删除 "t" 并将 116 加入总和。
结束时,两个字符串相等,115 + 116 = 231 就是符合条件的最小和。示例 2:
输入: s1 = "delete", s2 = "leet"
输出: 403
解释: 在 "delete" 中删除 "dee" 字符串变成 "let",
将 100[d]+101[e]+101[e] 加入总和。在 "leet" 中删除 "e" 将 101[e] 加入总和。
结束时,两个字符串都等于 "let",结果即为 100+101+101+101 = 403 。
如果改为将两个字符串转换为 "lee" 或 "eet",我们会得到 433 或 417 的结果,比答案更大。注意:
0 < s1.length, s2.length <= 1000。- 所有字符串中的字符ASCII值在
[97, 122]之间。
Solution
class Solution {
public:
int minimumDeleteSum(string s1, string s2)
{
int ws1 = s1.size();
int ws2 = s2.size();
int dp[ws1 + 1][ws2 + 1];
dp[0][0] = 0;
for (int i = 1; i <= ws1; ++i)
{
dp[i][0] = dp[i - 1][0] + s1[i - 1];
}
for (int i = 1; i <= ws2; ++i)
{
dp[0][i] = dp[0][i - 1] + s2[i - 1];
}
for (int i = 1; i <= ws1; ++i)
{
for (int j = 1; j <= ws2; ++j)
{
if (s1[i - 1] == s2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1];
}
else
{
dp[i][j] = min(
dp[i][j - 1] + s2[j - 1],
dp[i - 1][j] + s1[i - 1]
);
}
}
}
return dp[ws1][ws2];
}
};103. 二叉树的锯齿形层序遍历
Difficulty: 中等
给定一个二叉树,返回其节点值的锯齿形层序遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7返回锯齿形层序遍历如下:
[
[3],
[20,9],
[15,7]
]Solution - 无reverse
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> zigzagLevelOrder(TreeNode* root)
{
if (!root)
{
return {};
}
deque<TreeNode*> nodes_last;
deque<TreeNode*> nodes_next;
nodes_last.push_back(root);
bool r_to_l = false;
vector<vector<int>> result;
while (!nodes_last.empty())
{
vector<int> temp;
temp.reserve(nodes_last.size());
if (r_to_l)
{
while (!nodes_last.empty())
{
TreeNode* node = nodes_last.back();
nodes_last.pop_back();
if (node->right)
{
nodes_next.push_front(node->right);
}
if (node->left)
{
nodes_next.push_front(node->left);
}
temp.push_back(node->val);
}
}
else
{
while (!nodes_last.empty())
{
TreeNode* node = nodes_last.front();
nodes_last.pop_front();
if (node->left)
{
nodes_next.push_back(node->left);
}
if (node->right)
{
nodes_next.push_back(node->right);
}
temp.push_back(node->val);
}
}
result.push_back(move(temp));
r_to_l = !r_to_l;
nodes_next.swap(nodes_last);
}
return result;
}
};42. 接雨水
Difficulty: 困难
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 示例 2:
输入:height = [4,2,0,3,2,5]
输出:9提示:
n == height.length0 <= n <= 3 * 10<sup>4</sup>0 <= height[i] <= 10<sup>5</sup>
Solution - 暴力法
class Solution {
public:
int trap(vector<int>& height)
{
int n = 0;
int sum_rain = 0;
while (true)
{
int sum_wall_n = 0;
n++;
int left_wall = INT_MAX;
int right_wall = INT_MIN;
for (int i = 0; i < height.size(); ++i)
{
if (height[i] >= n)
{
sum_wall_n++;
left_wall = min(i, left_wall);
right_wall = max(i, right_wall);
}
}
if (sum_wall_n >= 2)
{
int rain = right_wall - left_wall - 1 - (sum_wall_n - 2);
sum_rain += rain;
}
else
{
break;
}
}
return sum_rain;
}
};一层一层判断, 当前层可存储雨水等于 当前层最左侧墙和当前层最右侧墙之间的数量 减去之间墙的数量 得到空位的数量 也就是雨水
时间复杂度O(n^2) 空间复杂度O(1).
另外一种暴力方法是每次计算当前位置最多积多少水, 上面的暴力方法是一层一层计算 这里是一列一列计算. 需要从当前位置分别向左和右遍历找到两边的最高墙
较矮的一边减去当前墙高度即为当前位置最多积累的雨水. 时间和空间复杂度同上
Solution - 动态规划 提前遍历出每个位置处的左边最高和右边最高
class Solution {
public:
int trap(vector<int>& height)
{
if (height.empty())
{
return 0;
}
const int HEI_SIZE = height.size();
vector<int> left_max;
vector<int> right_max;
left_max.resize(HEI_SIZE);
right_max.resize(HEI_SIZE);
left_max[0] = height[0];
right_max[HEI_SIZE - 1] = height[HEI_SIZE - 1];
for (int i = 1; i < HEI_SIZE; ++i)
{
left_max[i] = max(left_max[i - 1], height[i]);
}
for (int i = HEI_SIZE - 2; i >= 0; --i)
{
right_max[i] = max(right_max[i + 1], height[i]);
}
int sum_rain_ret = 0;
for (int i = 1; i < HEI_SIZE; ++i)
{
int rain = min(left_max[i], right_max[i]) - height[i];
sum_rain_ret += max(rain, 0);
}
return sum_rain_ret;
}
};Solution - 递减栈
class Solution {
public:
int trap(vector<int>& height)
{
if (height.empty())
{
return 0;
}
int sum_rain_ret = 0;
stack<int> height_stack;
for (int i = 0; i < height.size(); ++i)
{
while (!height_stack.empty() && height[i] >= height[height_stack.top()])
{
int last_wall = height_stack.top(); // last_wall的高度 小于 i的高度 也小于 llast_wall的高度
height_stack.pop();
if (height_stack.empty())
{
break;
}
int llast_wall = height_stack.top(); // 这里不进行pop()是因为
// llast_wall的高度 小于 lllast_wall llast_wall 可能小于i的高度 这之间依然可能积水
int distance = i - llast_wall - 1; // 间距
int rain = min(height[llast_wall], height[i]) - height[last_wall];
sum_rain_ret += rain * distance;
}
height_stack.push(i);
}
return sum_rain_ret;
}
};代码比较难理解 结合[4,2,0,3,2,5]输入走一遍就好理解了 ans=9
Solution - 双指针
class Solution {
public:
int trap(vector<int>& height)
{
if (height.empty())
{
return 0;
}
int left_max_sub = 0;
int right_max_sub = height.size() - 1;
int left = left_max_sub + 1;
int right = right_max_sub - 1;
int sum_rain_ret = 0;
while (left <= right)
{
if (height[left_max_sub] < height[right_max_sub])
{
if (height[left] < height[left_max_sub])
{
sum_rain_ret += height[left_max_sub] - height[left];
}
else
{
left_max_sub = left;
}
left++;
}
else
{
if (height[right] < height[right_max_sub])
{
sum_rain_ret += height[right_max_sub] - height[right];
}
else
{
right_max_sub = right;
}
right--;
}
}
return sum_rain_ret;
}
};left_max_sub一定是left左边最高的墙, 但是right_max_sub不一定是left右边最高的墙. 也就是说右边的墙高度 大于等于 right_max_sub
所以当left_max_sub的墙的高度小于right_max_sub的时候 上面的问题就不存在了, 因为取决于更矮的墙